

摘要:通过爬取网站上的新闻内容,可以实现新闻分类的功能。这一过程通常涉及数据抓取、数据清洗和分类算法的应用。通过爬虫程序从各大新闻网站获取数据,经过处理后,利用自然语言处理技术对新闻进行文本分析和分类。将新闻归类到不同的类别中,方便用户快速浏览和获取所需信息。这一过程有助于提高信息获取效率和准确性。
本文目录导读:
随着互联网的发展,新闻信息的传播速度越来越快,新闻网站的数量也在不断增加,如何有效地从众多新闻网站中爬取信息,并对这些新闻进行分类,成为了当前信息处理和数据分析领域的重要问题之一,本文旨在探讨如何通过爬取网站实现新闻分类,以期为相关领域的研究和实践提供有益的参考。
网站爬取技术
网站爬取技术,也称为网络爬虫技术,是一种自动获取网站数据的方法,通过模拟浏览器行为,网络爬虫可以获取网页的源代码,并从中提取所需的数据,在实现新闻分类的过程中,我们需要使用爬虫技术从新闻网站爬取相关的新闻数据。
常用的网站爬取技术包括正则表达式、 XPath 和 CSS 选择器等,这些技术可以帮助我们快速定位到网页中的新闻数据,并实现自动化提取,在实际应用中,我们需要根据目标网站的结构和特点选择合适的爬取技术。
新闻分类方法
新闻分类是新闻处理的重要环节,通过对新闻进行分类,可以方便用户快速找到感兴趣的新闻,常见的新闻分类方法包括基于关键词的分类、基于内容的分类和基于机器学习的分类等。
1、基于关键词的分类:通过提取新闻中的关键词,将新闻归类到相应的类别中,这种方法简单易行,但分类效果受限于关键词的选择和权重设置。
2、基于内容的分类:通过分析新闻的内容,提取文本特征,如主题、情感等,将新闻归类到相应的类别中,这种方法可以更好地反映新闻的实际内容,但需要较为复杂的文本处理技术。
3、基于机器学习的分类:利用机器学习算法,如支持向量机、神经网络等,对新闻进行分类,这种方法可以自动学习新闻的特征和分类规则,适用于大规模新闻数据的分类。
爬取网站实现新闻分类的步骤
1、确定目标网站:根据需求,选择需要爬取的新闻网站。
2、分析网站结构:了解目标网站的结构和特点,选择合适的爬取技术。
3、设计爬虫程序:根据目标网站的结构和特点,设计合适的爬虫程序,实现自动化爬取新闻数据。
4、数据预处理:对爬取到的新闻数据进行清洗、去重和格式化等预处理工作。
5、特征提取:根据所选的分类方法,提取新闻数据的特征。
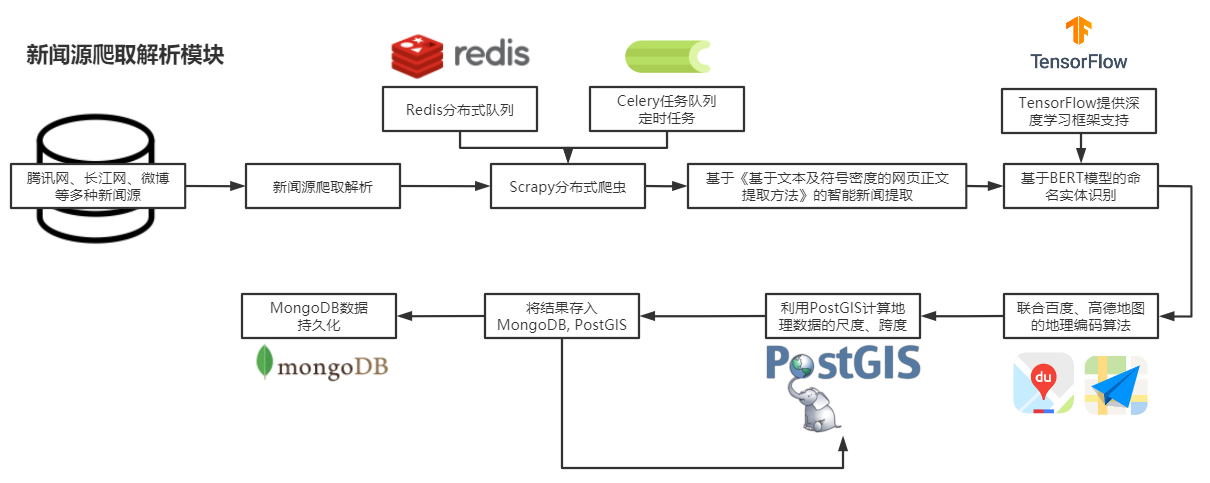
6、训练分类模型:根据提取的特征,选择合适的机器学习算法,训练分类模型。
7、测试和优化:使用测试数据集对分类模型进行测试,并根据测试结果对模型进行优化。
8、部署应用:将训练好的分类模型部署到实际应用中,实现新闻分类功能。
技术挑战与解决方案
1、反爬虫机制:一些新闻网站会采取反爬虫机制,限制爬虫程序的访问,解决方案是采用动态爬虫技术,模拟真实用户行为,绕过反爬虫机制。
2、数据清洗:爬取到的新闻数据可能存在噪声和错误,需要进行数据清洗和预处理,解决方案是采用合适的数据清洗方法和工具,如正则表达式、数据清洗库等。
3、特征提取:特征提取是新闻分类的关键环节,需要提取有效的特征以实现准确分类,解决方案是采用深度学习等技术,自动学习新闻数据的特征表示。

4、模型优化:模型优化是提高新闻分类效果的关键,解决方案是采用集成学习、迁移学习等方法,提高模型的泛化能力和鲁棒性。
案例分析
以某新闻网为例,该网站新闻报道种类繁多,包括政治、经济、社会、科技等多个领域,通过设计合适的爬虫程序,我们可以从该网站爬取相关的新闻数据,通过基于内容的分类方法,提取新闻文本特征,训练分类模型,在实际应用中,我们可以将训练好的模型部署到服务器,实现自动化新闻分类功能,通过这种方式,用户可以快速找到感兴趣的新闻,提高信息获取效率。
通过爬取网站实现新闻分类是一项具有实际意义的工作,在实现过程中,我们需要掌握网站爬取技术和新闻分类方法,并面临一些技术挑战,通过选择合适的技术和方法,我们可以有效地解决这些问题,实现自动化新闻分类功能,随着技术的发展和进步,我们可以期待更加智能和高效的新闻分类方法。
 京ICP备11000001号
京ICP备11000001号