

摘要:本文介绍了对垃圾分类网站的爬取,旨在探索数据获取与智能分类的新领域。通过爬取该网站上的数据,我们能够获取大量的垃圾分类信息,为智能分类提供数据支持。这不仅有助于提升垃圾分类的效率,还能推动智能分类技术的进一步发展。通过探索新的数据获取和处理方式,我们有望为环保事业做出更大的贡献。
本文目录导读:
随着互联网的普及和大数据时代的到来,数据爬取技术日益受到关注,在环保领域,垃圾分类网站的信息爬取显得尤为重要,本文将介绍爬取垃圾分类网站的重要性、应用场景、技术难点及解决方案,并探讨其在智能分类领域的未来发展。
垃圾分类网站的重要性
垃圾分类是一项重要的环保行动,对于减少污染、节约资源具有重要意义,随着各类垃圾分类网站的出现,这些平台提供了丰富的垃圾分类信息、政策法规、科普知识等资源,爬取这些网站的数据,对于政府、企业和个人而言具有重要意义:
1、政府:了解垃圾分类政策的执行效果,优化政策决策。
2、企业:了解行业动态,提高资源利用效率,优化生产流程。
3、个人:提高环保意识,学习垃圾分类知识,提高生活质量。
爬取垃圾分类网站的应用场景
1、数据统计与分析:爬取垃圾分类网站的数据,进行统计与分析,了解用户行为、需求及市场趋势。
2、垃圾分类知识普及:通过爬取垃圾分类网站的科普知识,整合并展示,提高公众对垃圾分类的认识。
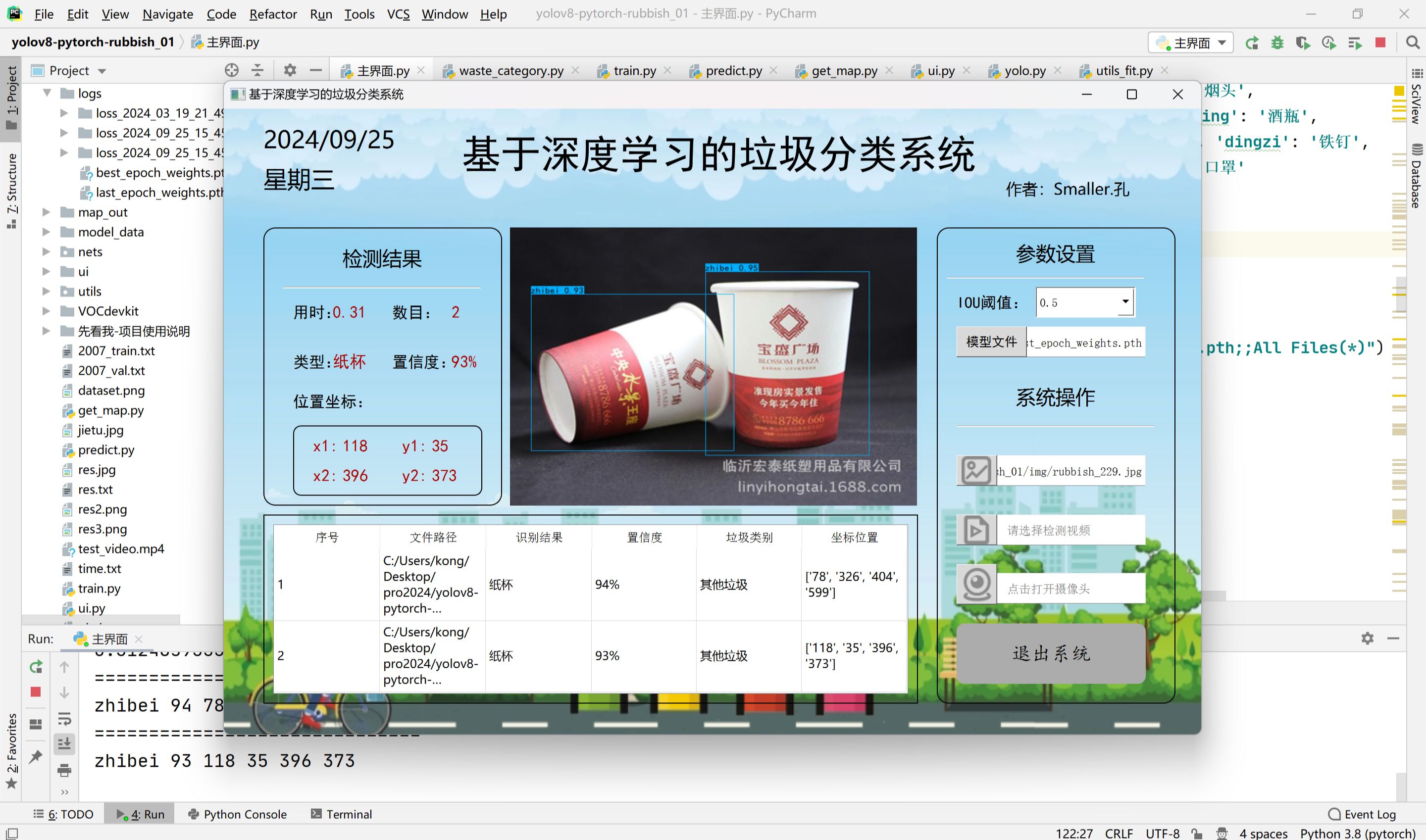
3、智能垃圾分类系统:将爬取的数据用于训练机器学习模型,实现智能分类,提高垃圾分类的效率和准确性。
技术难点及解决方案
在爬取垃圾分类网站的过程中,可能会遇到以下技术难点:
1、网站反爬虫机制:部分网站会采取各种措施来阻止爬虫访问,如动态加载、验证码等。
2、数据格式多样:垃圾分类网站的数据格式可能多样化,包括文本、图片、视频等,需要采用不同的处理方法。
3、数据清洗与整理:爬取的数据可能包含大量无关信息,需要进行数据清洗和整理。
针对以上难点,可以采取以下解决方案:
1、使用高级爬虫技术:采用动态爬虫、模拟浏览器等技术来应对反爬虫机制。
2、多样化数据解析:根据数据格式选择合适的数据解析方法,如正则表达式、OCR识别等。
3、数据清洗自动化:利用自然语言处理、机器学习等技术实现数据清洗自动化,提高数据处理效率。
爬取垃圾分类网站在智能分类领域的未来发展
随着人工智能技术的不断发展,爬取垃圾分类网站在智能分类领域的应用前景广阔,我们可以期待以下几个方面的发展:
1、实时数据抓取与分析:利用实时爬虫技术,对垃圾分类网站进行实时数据抓取与分析,为政府决策和企业运营提供实时数据支持。
2、智能垃圾分类系统优化:通过爬取的数据训练更先进的机器学习模型,优化智能垃圾分类系统的性能和准确性。
3、跨平台数据整合:整合多个垃圾分类网站的数据,形成全面的行业数据视图,为行业研究和市场趋势分析提供有力支持。
4、数据驱动的政策建议:政府可以根据爬取的数据分析结果,制定更具针对性的垃圾分类政策,提高政策效果。
5、公众参与与社区共建:通过爬取的数据了解公众需求,鼓励公众参与垃圾分类工作,形成社区共建的良性局面。
爬取垃圾分类网站对于获取相关数据、推动智能分类领域的发展具有重要意义,虽然在实际操作中可能会遇到一些技术难点,但通过采用先进的爬虫技术和数据处理方法,我们可以有效地解决这些问题,随着技术的不断进步,爬取垃圾分类网站在智能分类领域的应用前景将更加广阔。
 京ICP备11000001号
京ICP备11000001号