

摘要:分类信息网站采集是一项重要的数据挖掘过程,旨在从海量信息中提取有价值的宝藏。通过运用先进的爬虫技术和数据分析工具,我们能够快速收集、整理并分类展示各类信息,从而为用户提供便捷的数据查询和获取途径。这一过程不仅提高了数据利用效率,还为企业决策、市场研究和个人生活提供了有力支持。通过深入挖掘数据的宝藏,我们能够实现更高效的信息传递和更精准的数据分析。
本文目录导读:
随着互联网的发展,分类信息网站已经成为人们获取信息的重要途径之一,这些网站涵盖了各种领域的信息,如房产、招聘、二手商品等,为人们的生活和工作提供了极大的便利,如何从众多的分类信息网站中高效地采集数据,成为了一个值得研究的问题,本文将介绍分类信息网站采集的重要性、方法和技术挑战。
分类信息网站采集的重要性
分类信息网站采集对于企业和个人而言都具有重要意义,对于企业而言,通过采集分类信息网站的数据,可以更好地了解市场动态和竞争对手情况,为企业决策提供支持,这些数据还可以用于精准营销、客户关系管理等业务场景,对于个人而言,分类信息网站采集可以帮助我们快速找到所需的信息,提高生活和工作效率。
分类信息网站采集的方法
1、爬虫技术
爬虫技术是分类信息网站采集的主要手段之一,通过模拟浏览器行为,爬虫程序可以自动访问分类信息网站,获取页面数据并存储在本地,常见的爬虫技术包括Scrapy、PySpider等,使用爬虫技术时,需要注意遵守网站的爬虫协议,避免对网站造成不必要的负担。
2、API接口获取
除了爬虫技术,许多分类信息网站还提供了API接口,可以通过调用这些接口获取数据,这种方式相对简单、高效,但需要网站提供API接口,并且需要遵守接口的使用规则。
3、数据抓取工具
还可以使用一些数据抓取工具进行分类信息网站采集,如Octoparse、Web Data Extractor等,这些工具可以自动识别网页结构,提取所需数据,方便易用。
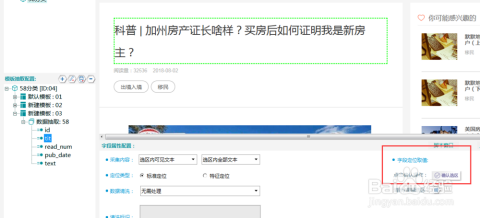
分类信息网站采集的技术挑战
1、数据清洗
采集到的数据往往需要进行数据清洗,以去除无关信息、纠正错误数据等,数据清洗是一项繁琐且需要专业技能的任务,需要耗费大量时间和精力。
2、反爬虫策略
许多分类信息网站采取了反爬虫策略,如限制访问频率、使用CAPTCHA验证等,给数据采集带来了一定的困难,需要采取相应措施应对这些反爬虫策略,以确保数据采集的顺利进行。
3、数据格式和标准化问题
不同分类信息网站的数据格式和标准化程度不同,这给数据采集和整合带来了挑战,需要采取合适的方法对数据进行处理,以确保数据的准确性和一致性。
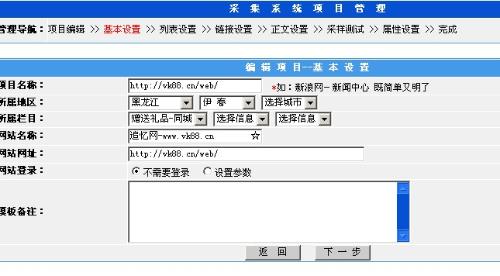
4、法律法规和道德伦理问题
在进行分类信息网站采集时,需要遵守相关法律法规和道德伦理规范,尊重网站的知识产权和隐私保护,否则可能会面临法律风险。
解决方案和建议
1、建立专业的数据清洗团队
为了应对数据清洗的挑战,可以建立专业的数据清洗团队,对数据进行预处理和清洗,确保数据的准确性和可靠性。
2、研究并应对反爬虫策略
针对反爬虫策略,可以通过研究网站的规则和技术,采取相应措施进行应对,使用代理IP、分布式爬虫等方式提高访问成功率。
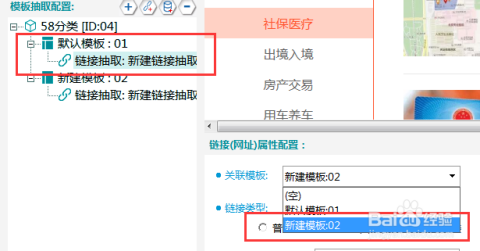
3、制定统一的数据格式和标准化规范
为了解决数据格式和标准化问题,可以制定统一的数据格式和标准化规范,对数据进行处理和整合,还可以利用数据映射等技术实现不同格式数据之间的转换。
4、遵守法律法规和道德伦理规范
在进行分类信息网站采集时,应遵守相关法律法规和道德伦理规范,尊重网站的知识产权和隐私保护,避免对网站造成不必要的负担。
分类信息网站采集对于企业和个人而言具有重要意义,本文介绍了分类信息网站采集的方法、技术挑战和解决方案,在实际应用中,应根据具体情况选择合适的方法和技术进行数据采集,并遵守相关法律法规和道德伦理规范。
 京ICP备11000001号
京ICP备11000001号